

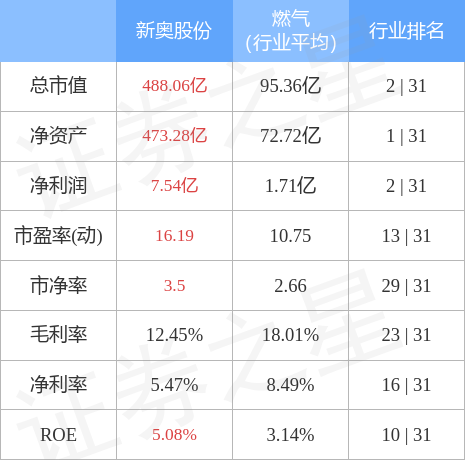
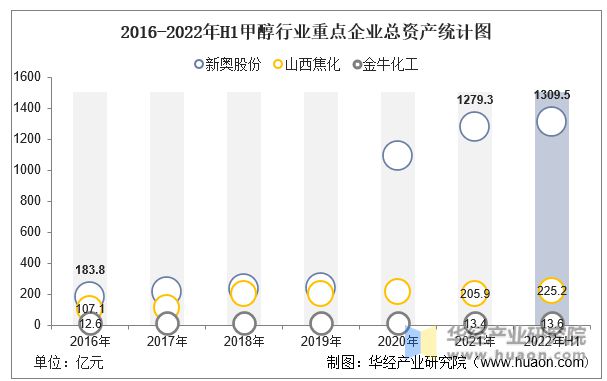
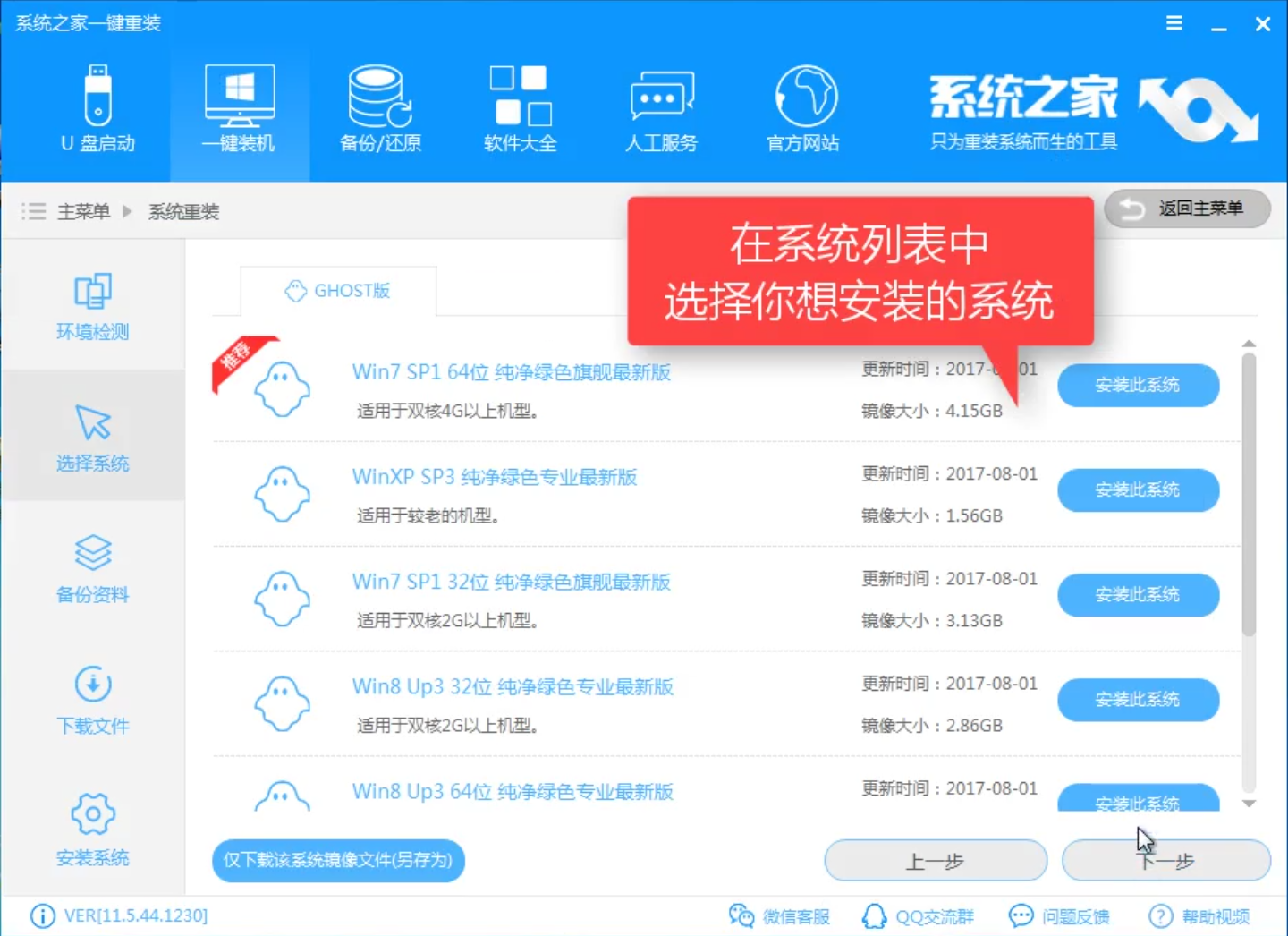
2024新奥正版资料免费提供第58期:如何使用Python进行数据分析
概述
在本期资料中,我们将详细介绍如何使用Python进行基本的数据分析。无论你是数据分析的初学者还是希望提升技能的进阶用户,本指南都将为你提供清晰的步骤和示例,帮助你掌握这一重要技能。
步骤1:安装Python和必要的库
首先,你需要在你的计算机上安装Python。你可以从Python官方网站下载并安装最新版本的Python。
接下来,安装一些常用的数据分析库,如pandas、numpy和matplotlib。你可以通过以下命令在终端或命令提示符中安装这些库:
pip install pandas numpy matplotlib
步骤2:导入库并加载数据
在你的Python脚本或Jupyter Notebook中,首先导入必要的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
然后,加载你要分析的数据。假设你有一个CSV文件,可以使用pandas的read_csv函数来加载数据:
data = pd.read_csv('your_data.csv')
步骤3:数据探索
在开始分析之前,先对数据进行初步探索。你可以使用head()函数查看数据的前几行:
print(data.head())
使用describe()函数获取数据的统计摘要:
print(data.describe())
步骤4:数据清洗
数据清洗是数据分析中非常重要的一步。你可以使用以下方法来处理缺失值和重复数据:
- 删除缺失值:
data.dropna(inplace=True)
- 删除重复行:
data.drop_duplicates(inplace=True)
步骤5:数据分析
现在,你可以开始进行数据分析了。例如,你可以计算某一列的平均值:
mean_value = data['column_name'].mean()
print(f'Mean value: {mean_value}')
你还可以使用groupby函数对数据进行分组分析:
grouped_data = data.groupby('category_column').mean()
print(grouped_data)
步骤6:数据可视化
数据可视化是数据分析的重要组成部分。你可以使用matplotlib来创建图表。例如,绘制某一列的直方图:
plt.hist(data['column_name'], bins=20)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Histogram of Column Name')
plt.show()
步骤7:保存分析结果
最后,你可以将分析结果保存到一个新的CSV文件中:
grouped_data.to_csv('analysis_results.csv')
总结
通过以上步骤,你已经学会了如何使用Python进行基本的数据分析。从安装必要的库到数据清洗、分析和可视化,每一步都为你提供了详细的指导和示例。希望这份指南能帮助你在数据分析的道路上更进一步。

如果你有任何问题或需要进一步的帮助,请随时参考本期资料或查阅相关文档。祝你在数据分析的学习中取得成功!







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号